Google AI Blog: Holistic Video Scene Understanding with ViP-DeepLab (googleblog.com)
Holistic Video Scene Understanding with ViP-DeepLab
Posted by Siyuan Qiao, Student Researcher and Liang-Chieh Chen, Research Scientist, Google Research People are able to retrieve the visua...
ai.googleblog.com
본 글은 위의 GoogleAI Blog에 Siyuan Qiao (Student Researcher and Liang-Chieh Chen, Research Scientist, Google Research)에 의해 게제된 ViP-DeepLab 에 관한 글을 읽고 해석 및 요약한 게시글 입니다.
사람들은 visual information을 보고 쉽게 3D 환경을 구축해낼 수 있다. - 사람은 2D 이미지에 포함된 제한된 소스로도 물체를 찾거나, 각 객체의 사이즈를 구분하거나, 3D 장면의 레이아웃을 재건할 수 있기 때문이다. 이러한 능력은 모호한 mapping 신호를 reconstruct(재건)할 수 있는 능력으로, inverse projection problem이라고도 불린다. 자율주행과 같은 Real-World Computer Vision 응용은 이러한 3D 객체 인식 및 위치구분, 클래스(물체의 종류) 구분 등의 능력에 많이 의존한다. 이미지로 부터 3D 세상을 재건하는 이러한 능력은 크게 아래 두 가지의 computer vision task로 나뉜다.
1. Monocular Depth Estimation : 한 장의 이미지에서 거리 정보 예측
2. Video Panotic Segmentation : 비디오 도메인에서의 panotic segmentation (instance + semantic)
기존 연구들은 이 두 가지의 task를 구분해서 보았으나, 이 두 가지를 하나의 모델로 통합하는 것은 더욱 쉽게 모델링을 전개할 수 있으며, 계산량 역시 아낄 수 있는 효과를 가져온다.
이러한 동기로 CVPR 2021에 googleAI는 “ViP-DeepLab: Learning Visual Perception with Depth-aware Video Panoptic Segmentation”를 제출하였다. 이 논문은 depth-aware video panoptic segmentation이라는 새로운 주제를 설정하여 앞서 말한 monocular depth estimation와 video panoptic segmentation을 해결하였다.
또한, 논문은 이 새로운 task를 위해 depth-aware video panoptic quality (DVPQ)이라는 새로운 metric을 적용한 dataset을 제안하여 depth estimation과 video panoptic segmentation을 함께 평가한다. 이를 만족하기 위해, 논문은 기존 Panoptic-DeepLab에 depth 예측을 하는 network branch를 달아 확장하여 ViP-DeepLab을 만들었다. 이 모델은 이미지 평면의 각 픽셀마자 panoptic segmentation과 monocular depth estimation을 함께 수행하여 state-of-the-art의 성능을 달성했으며, 그 성능은 아래 영상에서 확인할 수 있다.

이미지 설명
좌상단 : 입력되는 video frame
우상단 : Video panoptic segmentation 결과
좌하단 : 예측한 깊이
우하단 : 복원된 3D point
OverView
기존 Panoptic-DeepLab은 semantic segmentation, center prediction, center regression을 한 장의 사진(single frame)에 대해 할 수 있음에 반해, multi frame에 대해서 깊이를 예측하거나 이어지는 프레임에 대해 (한시적으로) instance ID 예측을 하는 능력은 떨어진다. ViP-DeepLab은 이러한 부가적인 예측을 두 개의 연속적인 프레임을 인풋으로 받음으로써 해결했다. 먼저, 첫 번째 프레임에서의 픽셀마다의 깊이 예측이 결과로 나오게 된다. 이에 ViP-DeepLab은 첫번째 프레임에서 결과물로 나오는 객체에 대해서만 각 프레임에서 center prediction을 수행한다. 이러한 과정을 center offset prediction이라 한다. 이러한 과정을 통해 ViP-DeepLab은 첫번째 프레임에 등장하는 모든 물체에 대해 이에 해당하는 픽셀을 그룹화하여 묶을 수 있게 된다. 이때, 첫번째 프레임에서 등장하지 않아 그룹화 되지 못한 픽셀들은 New instance로 취급되어 묶인다. 이러한 과정을 전체 비디오에 대해 수행하며 일시적인 연속 instance ID를 묶어서 panoptic prediction을 수행한다. (정리 : panoptic prediction이 semantic segmentation에 instance segmentaion을 합친 것과 같으므로, 기존 panoptic-DeepLab의 semantic segmentation 결과에 연속 비디오 프레임에서 얻은 instance segmenation 결과를 합쳐 Panoptic segmentation 결과를 출력하는 것. 도식화는 아래 그림 참고)

Results
Cityscapes-VPS, KITTI Depth Prediction, KITTI Multi-Object Tracking and Segmentation (MOTS) 를 벤치마크로 삼아 성능을 측정함.
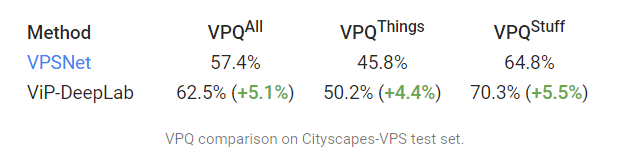
1. Video Panoptic Quality(VPQ) 비교 - VPSnet과의 VPQ metric 비교시 5.1% 가량 성능 향상.
2. Depth prediction 비교 - KITTI 모델과 비교 (SILog는 더 작은 수치가 더 좋음)

3. 새로운 metric 비교 - sMOTSA로는 KITTI MOTS car class에서 3등, pedestrain class에서 1등.

4. 최종적으로, 제안한 dataset을 DVPQ metric으로 비교

Conclusion
ViP-DeepLab은 간단한 구조로도 state-of-the-art의 성능을 달성했다. (Dual-path transformer module을 개발하여 end-to-end 구조의 panoptic segmentation을 제안한) MaX-DeepLab과 함께 ViP-DeepLab이 holistic understanding of scenes in the real world 연구 분야의 선두주자가 될 것임을 기대한다.
'딥러닝 공부 > Paper Review' 카테고리의 다른 글
| [Survey review] DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection 정리 및 요약 - 1 Intro (0) | 2021.03.29 |
|---|




