오랜만에 쓰는 NeRF 논문 리뷰
CVPR 2025 NeRF 논문 리뷰
논문 링크: https://arxiv.org/pdf/2410.16271
프로젝트 페이지: https://linjohnss.github.io/frugalnerf/
코드는 아직 미공개
Main Figure

Over all Comments
2장의 input으로도 빠른 학습과 좋은 성능을 동시에 달성
기존의 few-shot 논문들이 쓰는 여러가지 방법(Frequeuncy regularization, voxel grid, external prior) 등을
적절히 활용하여 상호보완한 논문
여전히 depth-prior(Ld)를 쓴다는 단점은 있고 학습의 복잡도를 아주 해결하지는 못했지만
복잡하다 =/= 나쁘다 이니 괜찮은 결과를 냈으니 Good.
그리고 모델을 엄청 타는 방법들도 아니라서 fexlible하다고 생각

아래는 논문 요약
의견은 회색 글씨 또는 (괄호)에 작성
그 외의 대부분의 내용은 논문에서 발췌
Abs
눈에 띄는 점은 Abs 완전 초반부터 특정 논문을 언급하면서 해당 논문들과 비교할 것임을 명시한다.
: ~~ FreeNeRF and SparseNeRF, use frequency regularization or pre-trained priors but struggle with complex scheduling and bias.
보통 few-shot NVS 계열들은 pre-trained prior가 필요하기 마련인데
Abs만 봤을때는 이런 prior 없이도 잘 작동하고 별도의 복잡한 학습 테크닉도 없는 것으로 보인다
(but, figure를 봤을 땐 depth prior가 있는 버전, 없는 버전으로 두가지가 존재하는 것 같다)
* leverages weight-sharing voxels across multiple scales
* cross-scale geometric adaptation scheme that selects pseudo ground truth depth based on reprojection errors across scales.
그 외 논문에서 명시하는 main contribution은 두 가지
weight-sharing voxel이라는 특이한 개념과 cross-scale geometric adaption을 사용한다.
Intro
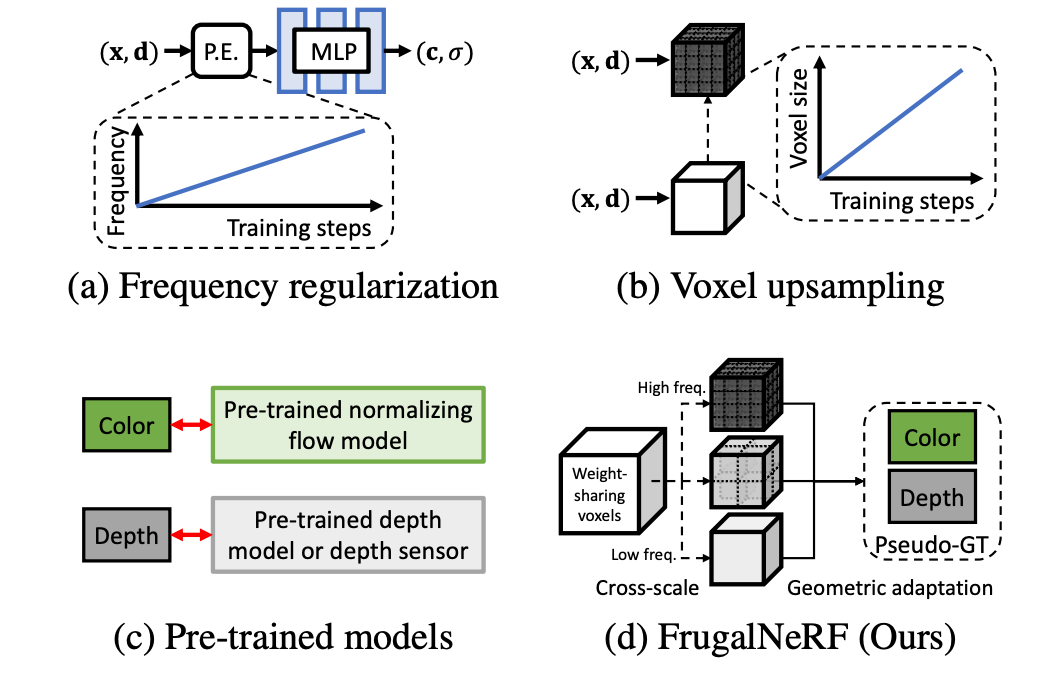
기존 방법들 a,b,c는 각각의 단점이 있다
(a) 대표적으로 FreeNeRF : 학습이 오래 걸림
(b) 다양한 scene에 잘되진 않음
(c) Pre-trained 된 prior 의존성이 높음
(-> 본인도 Pseudo GT를 쓰기 때문에 c에 대한 ablation이 있는지 확인 필요)
=> FrugalNeRF는 이 모든 방법들을 결합하여 빠른 수렴과 동시에 높은 퀄리티를 달성
* The most accurate scale becomes the pseudoground truth and guides the training across scales, thus eliminating the need for complex voxel upsampling schedules and enhancing generalizability across diverse scenes.
: Abs에서 언급했던 adaptation scheme에 대한 힌트를 살짝 준다
다양한 scale의 voxel grid를 사용해서 학습을 하되, 가장 reprojection error가 적은 scale이 pseudo GT가 되어 다른 두 scale의 학습을 주도한다. 단순한 sensitivity 기반의 방법으로 complex한 scheduling의 필요성을 줄여준다.
Methods
3.2 Overview of FrugalNeRF
The key feature is hierarchical subsampling with weight-sharing multi-scale voxels, ~ (Sec. 3.3).
To prevent overfitting in extreme few-shot scenarios, we apply geometric adaptation for regularization (Sec. 3.4),
along with novel view sampling and additional regularization losses to reduce artifacts (Sec. 3.5).
Related works에서 언급했던, voxel 구조가 일반적으로 갖는 overfitting 이슈를 해결하기 위해
geometry adaptation을 사용했고, 추가적으로 novel view sampling과 regularization loss를 적용했다는 스토리

3.3 Weight-Sharing Multi-Scale Voxels
FreeNeRF에서 사용했던 frequency regularization과 동일한 아이디어로,
lower resolution voxel이 전체적인 특성을 잡고 higher resolution voxel이 fine detail을 잡아주는 역할
특이한 점은 FreeNeRF처럼 순차적으로 학습하는 것이 아니라
Higher resolution voxel을 뽑아서 downsampling 으로 Lower resolution voxel을 만든다. (= weight-sharing)
이렇게 함으로써 geometry consistency를 유지할 수 있다고 함
추가적으로 model size나 memory size를 추가적으로 사용하지 않아도 됨
(그러나 향후 loss를 보면 각 scale별로 loss를 계산하기 때문에 코드를 봐야겠지만 memory 추가가 제로는 아닐듯)
loss는 각 크기의 voxel에서 각각 rendering 한 후 각 scale의 이미지에서 나온 loss를 전부 더해서 학습

3.4 Cross-scale geometric adaptation
cross-scale geometric adaptation은 few-shot scenarios의 한계를 GT depth data없이 해결하기 위해 도입한 방법
3.3에서 설명하듯이 다양한 scale의 voxel을 사용하게 되면 optimal scale을 찾는 것이 essential하기 때문
train view i 에서 각 voxel scale에 대해 depth 값을 계산 한 후
인접 view인 j에 i에서 계산한 RGB 값을 warping한다.
이를 실제 j의 RGB와 MSE 계산을 해서 그 error가 가장 적은 scale을 pseudo GT로 선정
pseudo GT scale의 Depth에 맞춰서 타 scale의 Depth를 학습한다 (eq(9))

개념적으로 설명하면 어느 정도 학습을 한 뒤, depth값을 계산해서 인근 view로 projection을 해보고 (일종의 validation view)
NeRF의 최종 loss은 color MSE loss가 가장 낮게 나오는 scale을 GT로 삼아서 나머지의 scale의 Depth를 학습시킨다는 것
특이한 점은 novel view과 train view (= train view i와 novel view j) 모두 해당 depth loss를 적용한다
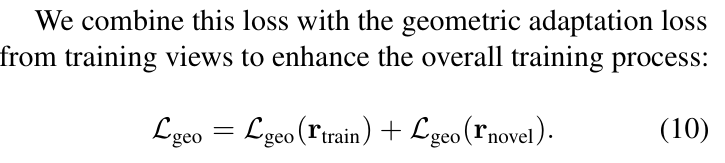
(albation을 보니까 Lgeo랑 후술할 Ld를 둘다 안쓴 실험이 없는 것 같은데 이 부분은 좀 마이너스다
section 3.4라는 중요한 위치를 내어준 것 치고는 ablation이 완벽히 변인통제된 것 같진 않다)
모쪼록 아래 Figure6를 보면 효과는 확실히 알 수 있다
depth 관련 loss다 보니 확실히 PSNR등 보다는 depth map에서 그 효과가 확실히 보인다

3.6 Total Loss
추가적으로 Lreg, Lsd, Ld를 사용함 (Ld는 depth prior loss로 선택적으로 적용)
Experiments
Eval: ViP-NeRF와 동일한 방법을 사용







