본 글은 위의 GoogleAI Blog에 Siyuan Qiao (Student Researcher and Liang-Chieh Chen, Research Scientist, Google Research)에 의해 게제된 ViP-DeepLab 에 관한 글을 읽고 해석 및 요약한 게시글 입니다.
사람들은 visual information을 보고 쉽게 3D 환경을 구축해낼 수 있다. - 사람은 2D 이미지에 포함된 제한된 소스로도 물체를 찾거나, 각 객체의 사이즈를 구분하거나, 3D 장면의 레이아웃을 재건할 수 있기 때문이다. 이러한 능력은 모호한 mapping 신호를 reconstruct(재건)할 수 있는 능력으로, inverse projection problem이라고도 불린다. 자율주행과 같은 Real-World Computer Vision 응용은 이러한 3D 객체 인식 및 위치구분, 클래스(물체의 종류) 구분 등의 능력에 많이 의존한다. 이미지로 부터 3D 세상을 재건하는 이러한 능력은 크게 아래 두 가지의 computer vision task로 나뉜다.
1. Monocular Depth Estimation : 한 장의 이미지에서 거리 정보 예측
2. Video Panotic Segmentation : 비디오 도메인에서의 panotic segmentation (instance + semantic)
기존 연구들은 이 두 가지의 task를 구분해서 보았으나, 이 두 가지를 하나의 모델로 통합하는 것은 더욱 쉽게 모델링을 전개할 수 있으며, 계산량 역시 아낄 수 있는 효과를 가져온다.
또한, 논문은 이 새로운 task를 위해 depth-aware video panoptic quality(DVPQ)이라는 새로운 metric을 적용한 dataset을 제안하여 depth estimation과 video panoptic segmentation을 함께 평가한다. 이를 만족하기 위해, 논문은 기존 Panoptic-DeepLab에 depth 예측을 하는 network branch를 달아 확장하여 ViP-DeepLab을 만들었다. 이 모델은 이미지 평면의 각 픽셀마자 panoptic segmentation과 monocular depth estimation을 함께 수행하여 state-of-the-art의 성능을 달성했으며, 그 성능은 아래 영상에서 확인할 수 있다.
출처 : Google AI Blog: Holistic Video Scene Understanding with ViP-DeepLab (googleblog.com)
기존 Panoptic-DeepLab은 semantic segmentation, center prediction, center regression을 한 장의 사진(single frame)에 대해 할 수 있음에 반해, multi frame에 대해서 깊이를 예측하거나 이어지는 프레임에 대해 (한시적으로) instance ID 예측을 하는 능력은 떨어진다. ViP-DeepLab은 이러한 부가적인 예측을 두 개의 연속적인 프레임을 인풋으로 받음으로써 해결했다. 먼저, 첫 번째 프레임에서의 픽셀마다의 깊이 예측이 결과로 나오게 된다. 이에 ViP-DeepLab은 첫번째 프레임에서 결과물로 나오는 객체에 대해서만 각 프레임에서 center prediction을 수행한다. 이러한 과정을 center offset prediction이라 한다. 이러한 과정을 통해 ViP-DeepLab은 첫번째 프레임에 등장하는 모든 물체에 대해 이에 해당하는 픽셀을 그룹화하여 묶을 수 있게 된다. 이때, 첫번째 프레임에서 등장하지 않아 그룹화 되지 못한 픽셀들은 New instance로 취급되어 묶인다. 이러한 과정을 전체 비디오에 대해 수행하며 일시적인 연속 instance ID를 묶어서 panoptic prediction을 수행한다. (정리 : panoptic prediction이 semantic segmentation에 instance segmentaion을 합친 것과 같으므로, 기존 panoptic-DeepLab의 semantic segmentation 결과에 연속 비디오 프레임에서 얻은 instance segmenation 결과를 합쳐 Panoptic segmentation 결과를 출력하는 것. 도식화는 아래 그림 참고)
출처 : Google AI Blog: Holistic Video Scene Understanding with ViP-DeepLab (googleblog.com)
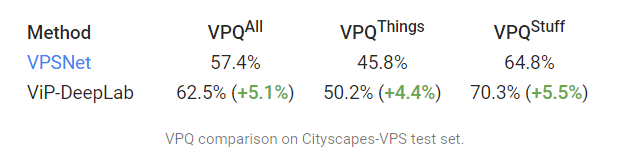
1. Video Panoptic Quality(VPQ) 비교 - VPSnet과의 VPQ metric 비교시 5.1% 가량 성능 향상.
출처 : Google AI Blog: Holistic Video Scene Understanding with ViP-DeepLab (googleblog.com)
2. Depth prediction 비교 - KITTI 모델과 비교 (SILog는 더 작은 수치가 더 좋음)
출처 : Google AI Blog: Holistic Video Scene Understanding with ViP-DeepLab (googleblog.com)
3. 새로운 metric 비교 - sMOTSA로는 KITTI MOTS car class에서 3등, pedestrain class에서 1등.
출처 : Google AI Blog: Holistic Video Scene Understanding with ViP-DeepLab (googleblog.com)
4. 최종적으로, 제안한 dataset을 DVPQ metric으로 비교
출처 : Google AI Blog: Holistic Video Scene Understanding with ViP-DeepLab (googleblog.com)
Conclusion
ViP-DeepLab은 간단한 구조로도 state-of-the-art의 성능을 달성했다. (Dual-path transformer module을 개발하여 end-to-end 구조의 panoptic segmentation을 제안한) MaX-DeepLab과 함께 ViP-DeepLab이 holistic understanding of scenes in the real world 연구 분야의 선두주자가 될 것임을 기대한다.
* Deepfake가 날이 갈수록 이슈가 되면서 학술적으로는 어떤 모델이 있는지 알아보기 위해 서베이 논문을 읽고,
관심분야만 요약 및 약간의 설명을 추가하여 정리한 글이다.
deepfake 기술을 이용해 합성한 사진_(출처 - https://www.youtube.com/watch?v=iDM69UEyM3w)
[DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection (ArXiv, 2020)]
: 위 논문은 2020년 1월 ArXiv에 등재된 논문으로, Deepfake와 관련된 task를 Face Manipulation이라고 명명한 후,
관련내용을 크게 7가지 항목으로 나누어 다루고 있다.
0. Abstraction
1. Introduction
2. Types of Facial Manipulations
3. Entire Face Synthesis
4. Identity Swap
5. Attribute Manipulation
6. Expression Swap
7. Other Face Manipulation Directions
2번 항목에서 Face Manipulation의 네 종류에 대한 간략한 소개를 하고 각 3,4,5,6번 항목에서 이를 자세히 다룬다.
(본 글에서는 최대한 초보자의 입장에서 0~2번을 정리하고 후속글로 4. Identity Swap에 대한 자세한 기술을 할 예정)
0. Abstract
공공 데이터셋의 접근성이 좋아짐과 동시에 GAN(Generative Adversarial Networks)과 같은 딥러닝 기술들이 빠르게 발전함에 따라 상당히 자연스러운 fake 컨텐츠들이 생성된다. 본 서베이 논문은 Deepfake 관련 기술을 네 가지로 나누어 그 생성과 감지 기술을 각각 조사했다. 그 네가지 항목은 아래와 같다
1) Entire Face synthesis
2) Identity Swap(DeepFakes)
3) Attribute Manipulation
4) Expression Swap
1. Introduction
- deepfakes의 어원 ?
: 우선 deepfake의 정의는 간략하게 딥러닝 기반의 기술로 한 사람의 얼굴을 다른 사람의 얼굴로 바꾸어 fake 비디오/사진을 만드는 것이다. 그 어원은, 2017년 reddit의 "deepfakes"라는 유저가 딥러닝 기술을 이용해서 유명 연예인의 얼굴을 포르노 영상에 합성할 수 있다고 주장하는 글이 올라와 관심을 받으면서 유저의 이름에서 비롯된 것으로 본다. 그 뒤 금융사기, 가짜 뉴스 등 여러 유해한 용도로 기술이 사용되면서 이에 대한 연구 목적의 관심 역시 증가했다. deepfakes 생성 기술이 연구 주제로서 관심을 받기 시작하면서 역으로 그 탐지기술도 주목을 받아 MFC(Media Forensics Challenge)2018, DFDC(DeepFake Detection Challenge) 등의 챌린지대회가 열렸다.
2. Types of Facial Manipulations
Facial Manipulation은 얼굴이 바뀌는 정도 (level of manipulation)에 따라 네 가지 task로 나눌 수 있다.
1) Entire Face synthesis - 얼굴 생성
2) Identity Swap(DeepFakes) - 얼굴 교체
3) Attribute Manipulation - 얼굴 속성 변경
4) Expression Swap - 표정 변경
1) Entire Face synthesis [얼굴 생성]
*출처 : DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection
: 존재하지 않는 얼굴을 존재하는 것처럼 생성해내는 기술. 대표적으로 StyleGAN 과 같은 powerful한 GAN으로 생성한다. 위의 예시 사진 역시 StyleGAN을 이용하여 생성한 예시이며, 여러 장의 사람 얼굴 사진을 먼저 저차원의 벡터로 mapping한 다음 다시 고차원의 이미지로 복원하는 과정을 반복하여 학습한다. 검증 단계 (생성 단계)에서는 임의의 noise 벡터를 주어서 사람의 얼굴로 복원해낼 수 있는지를 확인한다.
2) Identity Swap [얼굴 교체]
*출처 : DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection
: Face Swap 이라고도 불린다. Source 얼굴과 Target 얼굴의 사진을 여러 장 가지고 Autoencoder와 같은 구조로 학습 한 후 Source 이미지의 얼굴을 Target 이미지의 얼굴로 교체하는 task이다. 전통적인 Computer graphics를 응용해서 하는 방법과, Deep Learning을 응용해서 하는 방법으로 나뉜다. 본 글 상단에 아이언맨 영상에 톰크루즈를 합성한 이미지가 이것과 같은 Faceswap의 결과물이다.
*출처 : DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection
: Face editing 혹은 face Retouching 이라고도 불린다. 머리 색, 피부 색, 머리 스타일, 나이, 안경착용 여부 등등 다양한 얼굴의 한 속성을 변경하는 task이다. StyleGAN2나 StarGAN등의 GAN 모델을 대표적인 예시로 들 수 있다. 엄밀히 말하자면 StyleGAN2는 source 이미지를 입력으로 받는 것이 아니라 Entire Face synthesis와 같이 존재하지 않는 얼굴을 생성하는 과정에서 latent vector(or noise vector)에 약간의 변형을 줘서 다른 속성의 얼굴을 생성하는 방식이다.
4) Expression Swap [표정 변경]
*출처 : DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection
: face reenactment라고도 불린다. Source 이미지와 Target이미지로 학습 시킨 후에 Source 이미지의 특성을 전부 유지하되, Target이 짓던 표정으로 바꾸는 task이다. Face swap과의 차이를 말하자면, Face swap은 target 인물의 생김새와 source 이미지의 표정을 합성하고 Expression swap은 source 인물의 생김새에 target 이미지의 표정을 입히는 방식이다. 대표적인 방법으로 Face2Face등이 있다.